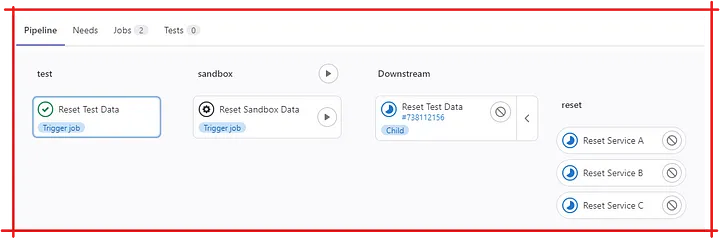
Gitlab parent-child pipeline
Scenario
You are building a pipeline that helps your team reset test data in different non-prod environments such as Test and Sandbox.
Under each environment, there are several application services or databases to clear. Let’s call them A, B, and C.
Trivial Approach
You can create 3 separate jobs for each environment
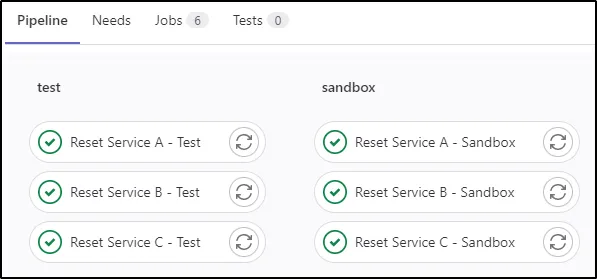
Trivial approach: 3 separate jobs for each environment
It will work. But there are 2 serious problems with this approach:
- High code duplication: The 2 jobs for 2 different environments share about 90% of their codes
- Problematic maintenance: Just imagine what you need to do to add a new service, or worse, support a new environment
stages:
- test
- sandbox
# TEST jobs
Reset Service A - Test:
stage: test
script: |
echo "Resetting service A's data in TEST"
echo "...busy-ing..."
echo "Reset A done"
Reset Service B - Test:
stage: test
script: |
echo "Resetting service B's data in TEST"
echo "...busy-ing..."
echo "Reset B done"
Reset Service C - Test:
stage: test
script: |
echo "Resetting service C's data in TEST"
echo "...busy-ing..."
echo "Reset C done"
# SANDBOX jobs
Reset Service A - Sandbox:
stage: sandbox
script: |
echo "Resetting service A's data in SANDBOX"
echo "...busy-ing..."
echo "Reset A done"
Reset Service B - Sandbox:
stage: sandbox
script: |
echo "Resetting service B's data in SANDBOX"
echo "...busy-ing..."
echo "Reset B done"
Reset Service C - Sandbox:
stage: sandbox
script: |
echo "Resetting service C's data in SANDBOX"
echo "...busy-ing..."
echo "Reset C done"
Parent-child approach
This approach solves the 2 problems identified earlier. There is exactly 1 job for 2 (or, in the future, more) environments. Adding a new job does not require duplicating it across all environments. Supporting a new environment does not require duplicating and modifying all 3 jobs.
Gitlab parent-child pipeline
Let’s see it in actions
The Parent pipeline
This is the main pipeline where we configure the 2 environments: “test” and “sandbox” as values of stages. We then define one job for each environment, each extends .common job definition but provides its own variables (e.g. ENV: "TEST" or ENV: "SANDBOX”). The key factor in .common job is the trigger:include configuration which, when executed, will trigger the jobs defined in the file .gitlab-reset-data.yml — the child pipeline.
stages:
- test
- sandbox
.common:
allow_failure: true
rules:
- when: manual
trigger:
include: .gitlab-reset-data.yml
Reset Test Data:
stage: test
extends: .common
variables:
ENV: "TEST"
Reset Sandbox Data:
stage: sandbox
extends: .common
variables:
ENV: "SANDBOX"
The Child pipeline
This is where the resetting jobs get defined, for each service A, B, and C. As we can see, there is only 1 job per service for ALL environments.
stages:
- reset
Reset Service A:
stage: reset
script: |
echo "Resetting service A's data in $ENV environment"
echo "...busy-ing..."
echo "Reset A done"
Reset Service B:
stage: reset
script: |
echo "Resetting service B's data in $ENV environment"
echo "...busy-ing..."
echo "Reset B done"
Reset Service C:
stage: reset
script: |
echo "Resetting service C's data in $ENV environment"
echo "...busy-ing..."
echo "Reset C done"
Sample Codes
Check out the sample code at my GitLab repository
For the trivial approach, click here.
comments powered by Disqus