There are 2 articles from https://vladmihalcea.com describing his analysis and solutions to Hibernate’s MultipleBagFetchException. The first one, appeared around 2020 (when I first researched this problem) or even earlier (2018?), offered an analysis of the problem and a solution using Hibernate’s EntityManager API. The second one appeared around Jun 2022, and offers a slightly different solution for JPA.
I will present below my understanding of his analysis, his solutions, and working sample codes which you can check out and validate your understanding and/or devise your own solutions.
The sample codes are available on my GitHub. I encourage you to check it out and follow along. If you do, you may want to POST [http://localhost:8080/posts/samples](http://localhost:8080/posts/samples) to set up sample data.
The entities: Post, PostComment and Tag.
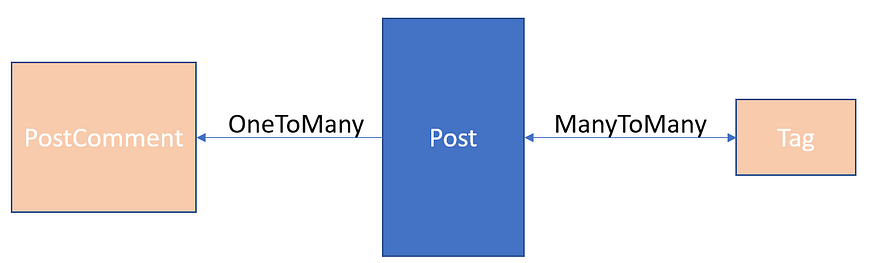
The entities: Post, PostComment and Tag
A Post represents a blog post with attributes such as id, title…
Readers of a post may leave comments. The relationship between PostComment to Post is ManyToOne :
public class PostComment {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String review;
@ManyToOne
private Post post;
}
There are a shared set of tags that a post may associate to:
public class Tag {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
}
The relationship between Post and Tag is ManyToMany using a JoinTable. The relationship between Post and PostComment is OneToMany. The full code of Post is available below:
public class Post {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String title;
@OneToMany(
mappedBy = "post",
cascade = CascadeType.ALL,
orphanRemoval = true
)
private List<PostComment> comments = new ArrayList<>();
@ManyToMany(
cascade = {
CascadeType.PERSIST,
CascadeType.MERGE
}
)
@JoinTable(
name = "post_tag",
joinColumns = @JoinColumn(name = "post_id"),
inverseJoinColumns = @JoinColumn(name = "tag_id")
)
private List<Tag> tags = new ArrayList<>();
}
Retrieve Posts with minimum number of DB queries
There are 3 ways of retrieving Posts with a lesser number of DB queries
#1 Retrieve **Post** entities only and let Hibernate issue queries to retrieve **Tag** and **PostComment** entities associated with each **Post**
@Query("select distinct p\\n" +
" from Post p")
List<Post> findAll_additionalFetching();
The number of DB queries is 1 + 2n with n being the number of Post entities retrieved
- 1 query to retrieve
Postentities - 2 queries for each
Postto retrieve its associatedPostCommentandTag
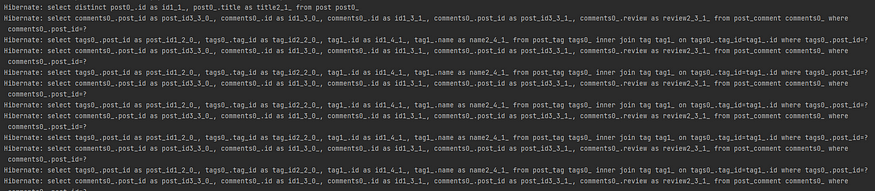
#2 Retrieve **Post** and associated **PostComment** (or **Tag**), and let Hibernate issue queries to retrieve **Tag** associated for each **Post**
@Query("select distinct p\\n" +
" from Post p\\n" +
" join fetch p.comments")
List<Post> findAll_fetchComments();
The number of DB queries is 1 + n with n being the number of Post entities retrieved
- 1 query to retrieve
Postentities and their associatedPostCommententities - 1 query for each
Postto retrieve its associatedTag

#3 Retrieve both **PostComment** and **Tag** associations along with **Post** in a single query
@Query("select p\\n" +
" from Post p\\n" +
" left join fetch p.comments\\n" +
" left join fetch p.tags")
List<Post> findAll_fetchCommentsAndTags();
BUT it does not work. The server will not even start because of The server fails to start with MultipleBagFetchExceptionorg.hibernate.loader.MultipleBagFetchException: cannot simultaneously fetch multiple bags: [Post.comments, Post.tags] thrown by Hibernate

Why Hibernate throws MultipleBagFetchException?
Vlad Mihalcea explained it best:
The reason why a
_MultipleBagFetchException_is thrown by Hibernate is that duplicates can occur, and the unordered_List_, which is called a bag in Hibernate terminology, is not supposed to remove duplicates.
Indeed, as the article and the StackOverFlow thread pointed out, changing Post’s associations from List to Set “fix” the error.
public class Post {
...
private Set<PostComment\> comments = new HashSet<>();
private Set<Tag\> tags = new HashSet<>();
...
}
BUT it’s not proper. Changing from List to Set may remove the obstacle for Hibernate to process the result set, but the generated query is very inefficient as it involves a cartesian product between Post, PostComment and Tag (technically, the join product between Post + PostComment intermediary result and Post + Tag intermediary result). This approach’s performance penalty in terms of processing cost and memory is undesirable.
The solution: use 2 queries and leverage JPA/Hibernate’s first-level cache and Persistence Context
Let’s look at the solution
/****PostRepository ****/
@Query("select distinct p\\n" +
" from Post p\\n" +
" join fetch p.comments")
List<Post> findAll_fetchComments();
@Query("select distinct p\\n" +
" from Post p\\n" +
" join fetch p.tags")
List<Post> findAll_fetchTags();
/**** PostController ****/
@GetMapping("/fetch-all")
public List<Post> fetchAll() {
var posts = postRepository.findAll_fetchComments();
return postRepository.findAll_fetchTags();
}
The first query postRepository.findAll_fetchComments() fetches Post and all associated PostComment entities.
The second query postRepository.findAll_fetchTags() fetches Postand all associated Tagentities. Because the first query already retrieved and stored all Post entities in the Persistence Context, the Post and Tag entities from the second query are merged into the same Post entities that are already populated with associated PostComment entities
As we can see from the console, there are only 2 queries issued to DB

Result from http://localhost:8080/posts/fetch-all
A Possible Downside
Assuming we want to apply some condition to filter the Post entities. Let’s find Post with odd id
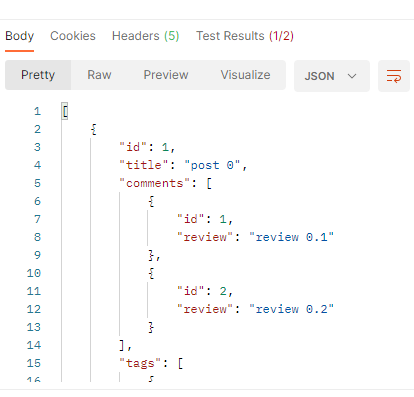
Result of http://localhost:8080/posts/odd
@Query("select distinct p\\n" +
" from Post p\\n" +
" join fetch p.comments\\n" +
" where p.id % 2 = 1")
List<Post> findOddPosts_fetchComments();
@Query("select distinct p\\n" +
" from Post p\\n" +
" join fetch p.tags\\n" +
" where p.id % 2 = 1")
List<Post> findOddPosts_fetchTags();
As you may notice, we need to duplicate the same condition where p.id % 2 = 1 in both queries.
In a real project, the filtering condition may not be this simple. We should avoid duplicating complex code if possible
Or someone may forget to update a query if the condition changes in the distant future. Trust me, debugging that is not pleasant at all.
Filtering-only-once solution
Let’s try this filtering-only-once solution to find all even-id posts
@Query("select distinct p\\n" +
" from Post p\\n" +
" join fetch p.comments\\n" +
" where p.id % 2 = 0")
List<Post> findEvenPosts_fetchComments();
@Query("select distinct p\\n" +
" from Post p\\n" +
" join fetch p.tags\\n" +
" where p in :posts")
List<Post> fetchTags(@Param("posts") List<Post> posts);
The first query defines the main filtering criteria and fetches the Post entities along with the associated PostComment records.
The second query simply fetches all identified Post entities using p in :posts condition along with their associated Tag entities.
Even if the filtering condition is complex, we only have to code it in one place. That greatly simplifies the code’s maintainability.

Result of http://localhost:8080/posts/even
There is a possible problem with this approach: the number of Post entities may be too high to fit in the IN condition. While it’s a valid concern, I think it does not happen often, especially if we have good filtering conditions or apply pagination techniques.